
Der Satz der totalen Wahrscheinlichkeit ist das Werkzeug, mit dem ich ein Ereignis in nachvollziehbare Teilfälle zerlege, statt nur mit einer nackten Gesamtzahl zu arbeiten. Genau darin liegt sein praktischer Wert: Aus bedingten Wahrscheinlichkeiten entsteht eine saubere Gesamtaussage, und die Rechnung bleibt transparent. In diesem Artikel zeige ich, wie die Formel wirklich gelesen wird, wie man sie am Baumdiagramm anwendet, wo sie in der Praxis auftaucht und welche Fehler eine gute Rechnung schnell entwerten.
Die Gesamtwahrscheinlichkeit entsteht aus sauber getrennten Fällen
- Ein Ereignis wird über mehrere disjunkte Teilfälle zusammengesetzt.
- Jeder Teilfall liefert einen Anteil über eine bedingte Wahrscheinlichkeit.
- Die Anteile werden mit den Fallwahrscheinlichkeiten gewichtet und addiert.
- Im Alltag hilft die Regel besonders bei Tests, Klassifikationen und Qualitätskontrollen.
- Für Rückwärtsfragen, etwa „Wie wahrscheinlich ist die Ursache?“, braucht man meist Bayes.
Was der Satz in der Praxis eigentlich macht
Ich lese die totale Wahrscheinlichkeit nicht als Sonderformel, sondern als Denkweise: Ein Ereignis tritt nicht „einfach so“ ein, sondern oft über mehrere mögliche Wege. Wenn ein Produkt entweder fehlerhaft oder intakt sein kann, wenn ein Testergebnis aus verschiedenen Ursachen entstehen kann oder wenn eine Entscheidung von mehreren Ausgangslagen abhängt, dann zerlege ich das Zielereignis in diese Fälle und rechne jeden Anteil getrennt aus.
Der entscheidende Punkt ist dabei die Verbindung von gemeinsamer Wahrscheinlichkeit und bedingter Wahrscheinlichkeit. Aus jedem Fall entsteht zunächst ein Schnittereignis wie P(A ∩ B_i). Dieses Schnittereignis kann ich als P(A | B_i) · P(B_i) schreiben. Genau daraus baut sich die Gesamtwahrscheinlichkeit zusammen. Die Formel ist also keine Zauberei, sondern eine kontrollierte Summation über mehrere Wege zum selben Ergebnis.
Das ist besonders nützlich, wenn die direkte Berechnung von P(A) unübersichtlich wäre. Sobald ich die Welt in Fälle zerlegen kann, wird das Problem meist deutlich handhabbarer. Und genau an dieser Stelle lohnt sich ein sauberer Blick auf die Formel selbst.
Die Formel ohne Stolperfallen
Für ein vollständiges System von disjunkten Ereignissen B_1, B_2, ..., B_n gilt:
P(A) = Σi=1n P(A | Bi) · P(Bi)
Die Bedingungen dahinter sind wichtig und werden in schnellen Rechnungen gern übersehen: Die Fälle müssen sich gegenseitig ausschließen, und zusammen müssen sie den gesamten Ergebnisraum abdecken. In der Sprache der Stochastik nennt man das eine Partition. Wenn nur zwei Fälle vorliegen, schreibt man die Formel oft in der kompakteren Form
P(A) = P(A | B) · P(B) + P(A | Bc) · P(Bc)
Das Gegenereignis Bc ist dabei nur die zweite Seite derselben Einteilung. Im stetigen Fall ersetzt man die Summe durch ein Integral, weil die Fälle dann nicht mehr endlich, sondern kontinuierlich beschrieben werden. Für die meisten Alltags- und Prüfungsaufgaben reicht jedoch die diskrete Form völlig aus.
Wenn die Struktur steht, wird die Formel auf dem Papier oft erstaunlich kurz. Die eigentliche Arbeit liegt dann nicht im Rechnen, sondern im sauberen Aufteilen der Fälle. Genau das sieht man im Baumdiagramm besonders gut.
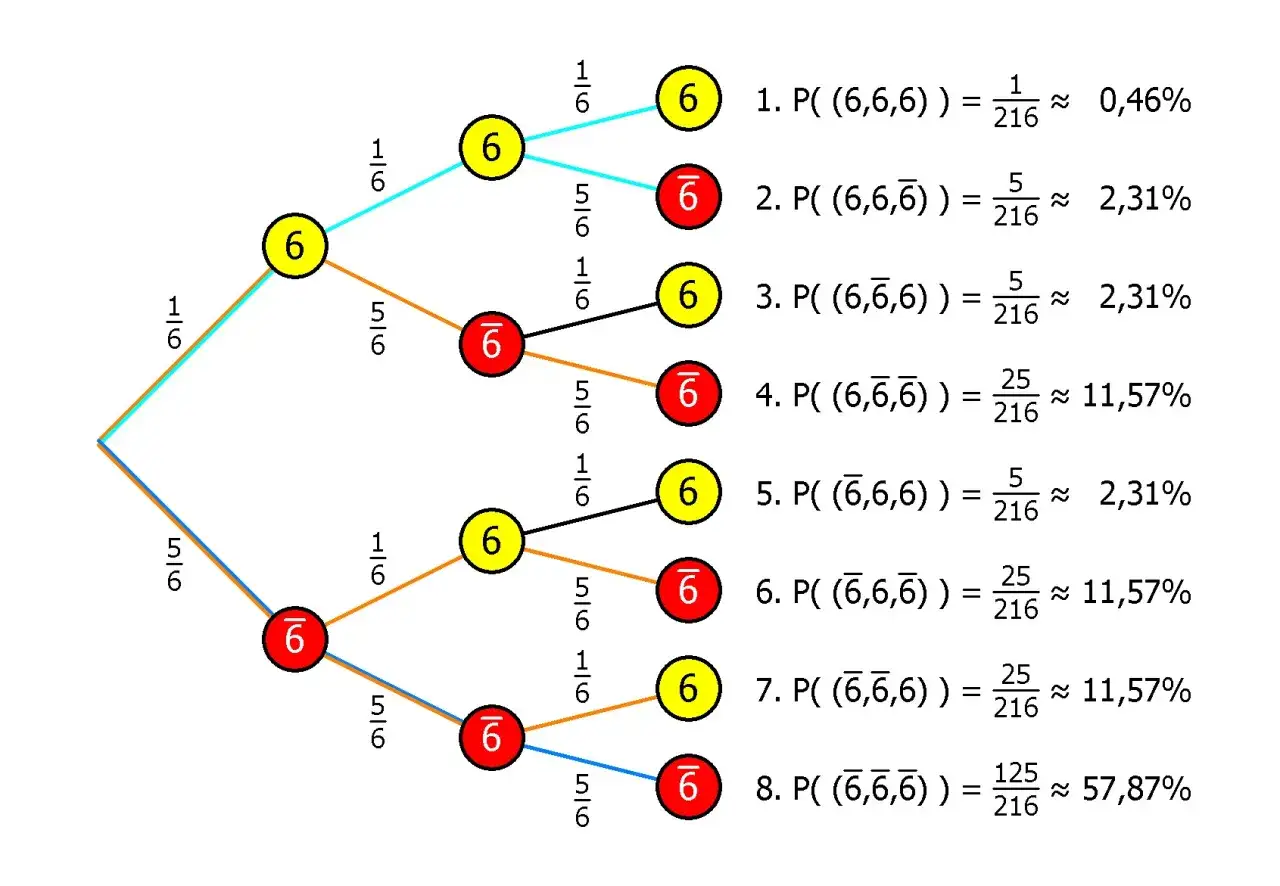
So lese ich ein Baumdiagramm
Ein Baumdiagramm ist für mich nicht Dekoration, sondern ein Rechenplan. Es zwingt dazu, die Reihenfolge der Bedingungen sauber festzuhalten und verhindert, dass man Pfade versehentlich doppelt oder gar nicht berücksichtigt.
- Ich definiere zuerst die Fälle, zum Beispiel „defekt“ und „nicht defekt“.
- Dann schreibe ich die Wahrscheinlichkeiten der Fälle an die ersten Äste.
- An den folgenden Ästen notiere ich die bedingten Wahrscheinlichkeiten, also etwa die Trefferquote eines Tests innerhalb jedes Falls.
- Für jeden Pfad multipliziere ich entlang des Astes.
- Am Ende addiere ich alle Pfade, die zum gesuchten Ereignis führen.
Diese Reihenfolge klingt banal, ist aber die häufigste Fehlerquelle in Klausuren und in der Praxis. Wer erst addiert und dann multipliziert, verliert schnell die Struktur des Problems. Wer die Fälle nicht vollständig trennt, rechnet mit einem unvollständigen Modell. Und wer die Pfade nicht konsequent liest, landet bei Zahlen, die formal hübsch aussehen, aber inhaltlich falsch sind.
Wie stark das ins Gewicht fällt, sieht man gut an einem konkreten Beispiel aus der Qualitätskontrolle.
Ein Beispiel aus der Qualitätskontrolle
Angenommen, in einer Produktion sind 3 % der Teile fehlerhaft. Ein Prüfsystem erkennt fehlerhafte Teile mit einer Trefferquote von 90 %. Bei fehlerfreien Teilen löst es trotzdem in 4 % der Fälle einen Alarm aus. Gesucht ist die Gesamtwahrscheinlichkeit für einen Alarm.
| Fall | Wahrscheinlichkeit des Falls | Bedingte Alarmwahrscheinlichkeit | Beitrag zum Gesamtergebnis |
|---|---|---|---|
| Teil ist fehlerhaft | 0,03 | 0,90 | 0,03 × 0,90 = 0,027 |
| Teil ist fehlerfrei | 0,97 | 0,04 | 0,97 × 0,04 = 0,0388 |
| Gesamt | 1,00 | – | 0,0658 |
Die Gesamtwahrscheinlichkeit für einen Alarm beträgt also 6,58 %. Das ist ein gutes Beispiel dafür, warum die reine Intuition oft täuscht: Obwohl fehlerhafte Teile nur 3 % ausmachen, wird der Alarm nicht nur durch echte Defekte ausgelöst, sondern auch durch Fehlalarme bei den vielen guten Teilen. Der größere Anteil am Gesamtergebnis kommt hier sogar von den fehlerfreien Teilen.
Wenn ich an dieser Stelle die nächste Frage stelle, dann ist es meist nicht mehr „Wie groß ist der Alarm insgesamt?“, sondern „Wie wahrscheinlich ist ein Defekt, wenn der Alarm بالفعل ausgelöst wurde?“. Genau dort beginnt die enge Verbindung zu Bayes.
Warum Bayes den Satz fast immer mitbenutzt
Ich trenne diese beiden Werkzeuge gern sauber: Die totale Wahrscheinlichkeit beantwortet Vorwärtsfragen, Bayes beantwortet Rückwärtsfragen. Vorwärtsfrage heißt: Aus den Ursachen und Teilfällen die Gesamtwahrscheinlichkeit berechnen. Rückwärtsfrage heißt: Aus einer beobachteten Wirkung auf die Ursache schließen.
Der Zusammenhang ist direkt. Wenn ich die Ereignisse B_i als vollständige Fallunterscheidung nehme, dann gilt
P(A) = Σi P(A ∩ Bi) = Σi P(A | Bi) · P(Bi).
Genau dieser Ausdruck steht oft im Nenner der Bayes-Formel. Deshalb wirkt Bayes auf den ersten Blick wie eine eigenständige Regel, hängt aber rechnerisch fast immer an derselben Struktur. Wer die totale Wahrscheinlichkeit nicht sauber beherrscht, scheitert in Bayes-Aufgaben meistens nicht am Bayes-Ansatz selbst, sondern am falsch berechneten Nenner.
Zur Orientierung hilft mir in der Praxis ein kurzer Vergleich:
| Frage | Typische Rechnung | Wofür geeignet |
|---|---|---|
| Wie groß ist die Gesamtwahrscheinlichkeit eines Ereignisses? | Summe über alle Fälle mit P(A | B_i) · P(B_i)
|
Wenn ein Ereignis über mehrere Ursachen eintreten kann |
| Wie wahrscheinlich ist die Ursache bei beobachteter Wirkung? | Bayes mit dem Nenner aus der totalen Wahrscheinlichkeit | Wenn man aus Daten auf eine Klasse, Ursache oder Herkunft schließen will |
Gerade in medizinischen Tests, Klassifikationsmodellen oder Qualitätsprüfungen ist diese Unterscheidung praktisch entscheidend. Manchmal ist das Ergebnis mathematisch korrekt, aber inhaltlich falsch interpretiert, weil die Richtung der Frage nicht stimmt. Darum schaue ich am Ende immer noch einmal auf die Fallstruktur selbst.
Worauf ich bei Rechnungen mit Fällen immer achte
Wenn ich mit der totalen Wahrscheinlichkeit arbeite, prüfe ich fast immer dieselben Punkte. Sie wirken simpel, sparen aber die meisten Denkfehler:
- Die Fälle müssen zusammen vollständig sein.
- Die Fälle dürfen sich nicht überschneiden.
- Jeder Fall braucht eine eigene bedingte Wahrscheinlichkeit.
- Ich darf
P(A | B)nicht mitP(B | A)verwechseln. - Ich muss alle relevanten Pfade addieren, nicht nur den naheliegenden.
- Bei realen Daten frage ich mich, ob die Wahrscheinlichkeiten geschätzt oder wirklich belastbar sind.
Der letzte Punkt wird oft unterschätzt. In Lehrbuchaufgaben sind die Zahlen exakt vorgegeben. In der Praxis stammen sie aber häufig aus Messreihen, Studien oder Modellen. Dann hängt die Qualität des Ergebnisses nicht nur von der Formel ab, sondern auch von der Qualität der Eingabedaten. Kleine Stichproben, verzerrte Tests oder schlecht definierte Fallgruppen können die Aussagekraft spürbar schwächen.
Ich setze den Satz der totalen Wahrscheinlichkeit deshalb nie blind ein. Ich prüfe zuerst die Struktur des Problems, dann die Fälle, dann die Bedingungen. Wenn diese drei Ebenen stimmen, ist die Rechnung meist kurz und robust. Wenn sie nicht stimmen, rettet auch eine saubere Formel nichts mehr.
Wer die Formel wirklich verstanden hat, erkennt sie in vielen Aufgaben sofort wieder: überall dort, wo ein Ereignis aus mehreren Ursachen entsteht. Genau diese Sichtweise macht den Unterschied zwischen bloßem Ausrechnen und sauberen stochastischen Entscheidungen. Und sie ist der Punkt, an dem die totale Wahrscheinlichkeit vom Rechentrick zum verlässlichen Denkwerkzeug wird.